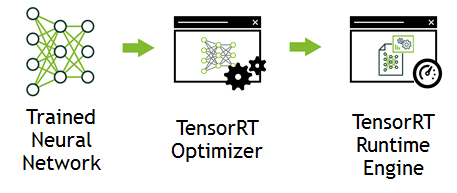
Deep Learning Inference Optimizer and Runtime Engine
NVIDIA TensorRT™ is a high-performance deep learning inference optimizer and runtime for deep learning applications. TensorRT can be used to rapidly optimize, validate and deploy trained neural network for inference to hyperscale data centers, embedded, or automotive product platforms.
Developers can use TensorRT to deliver fast inference using INT8 or FP16 optimized precision that significantly reduces latency, as demanded by real-time services such as streaming video categorization on the cloud or object detection and segmentation on embedded and automotive platforms. With TensorRT developers can focus on developing novel AI-powered applications rather than performance tuning for inference deployment. TensorRT runtime ensures optimal inference performance that can meet the needs of even the most demanding throughput requirements.
What’s New in TensorRT 2
TensorRT 2 is now available as a free download to the members of the NVIDIA Developer Program.
- Deliver up to 45x faster inference under 7 ms real-time latency with INT8 precision
- Integrate novel user defined layers as plugins using Custom Layer API
- Deploy sequence based models for image captioning, language translation and other applications using LSTM and GRU Recurrent Neural Networks (RNN) layers
TensorRT 3 for Volta GPUs- Interest List
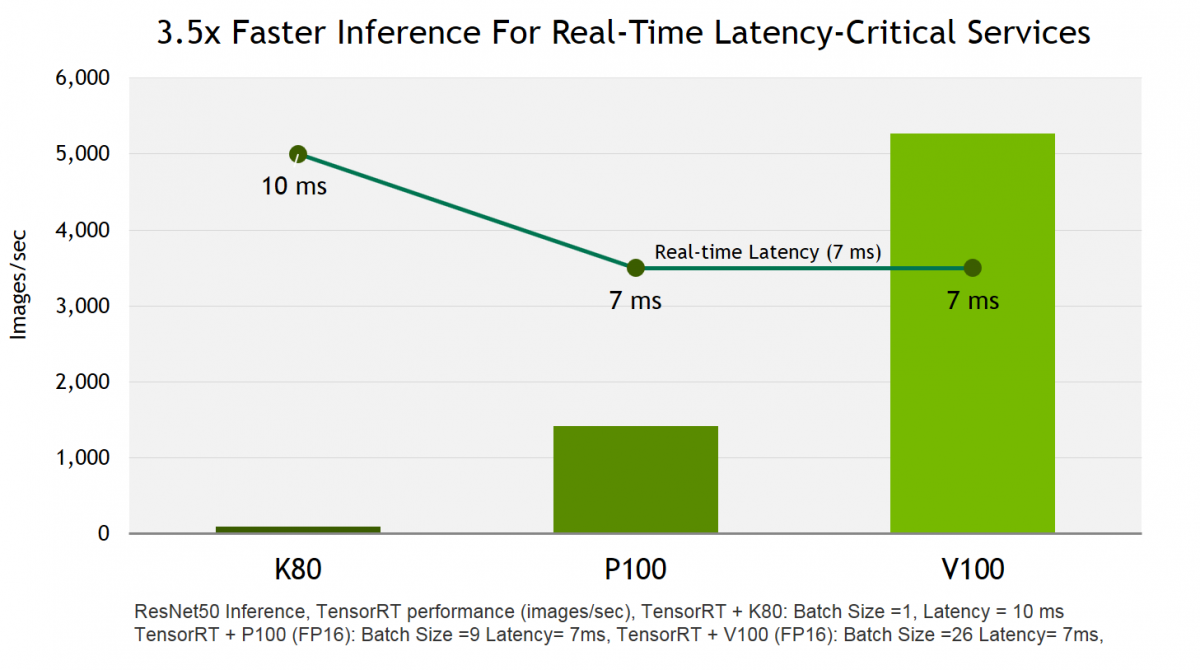
TensorRT 3 delivers 3.5x faster inference on Tesla V100, powered by Volta vs. Tesla P100. Developers can optimize models trained in TensorFlow or Caffe deep learning frameworks to generate runtime engines that maximizes inference throughput, making deep learning practical for latency-critical services in hyperscale datacenters, embedded, and automotive production environments.
With support for Linux, Microsoft Windows, BlackBerry QNX and Android operating systems developers can deploy AI-powered everywhere, from data centers to mobile, automotive and embedded edge devices.
Sign up below to be notified when TensorRT 3 becomes available.